
大话R-CNN家族秘史
1. R-CNN (Region-based Convolutional Neural Networks)
导言
Object detection(物体检测)需要多物体识别 + 定位多个物体
如果采用暴力滑窗的方式,则需要找许多位置,而且还要安排大小不同的框子
我怀疑你这是在刁难我胖虎,哦不,刁难我 GPU ( ╯-_-)╯┴—┴
R-CNN横空出世,她和 Region Proposal 必将为这个混沌的世界带来电闪雷鸣
如上所说,R-CNN解决了一个很关键的问题,避免产生很多不必要的框子,用的是啥好办法呢?Region Proposal(候选区域),这样问题就转变成找出可能含有物体的区域/框(也就是候选区域/框,比如选2000个候选框),这些框之间是可以互相重叠互相包含的,这样我们就可以避免暴力枚举所有框了。
R-CNN的大致结构:

步骤说明:
- 输入测试图像
- 利用选择性搜索Selective Search算法在图像中从下到上提取2000个左右的可能包含物体的候选区域Region Proposal
- 因为取出的区域大小各自不同,所以需要将每个Region Proposal缩放(warp)成统一的227x227的大小并输入到CNN,将CNN的fc7层的输出作为特征
- 将每个Region Proposal提取到的CNN特征输入到SVM进行分类
具体步骤则如下
步骤一:训练(或者下载)一个分类模型(比如AlexNet)
步骤二:对该模型做fine-tuning
将分类数从1000改为21,比如20个物体类别 + 1个背景
去掉最后一个全连接层
步骤三:特征提取
提取图像的所有候选框(选择性搜索Selective Search)
对于每一个区域:修正区域大小以适合CNN的输入,做一次前向运算,将第五个池化层的输出(就是对候选框提取到的特征)存到硬盘
- 注意:每个region proposal都要单独提取特征,这将耗费大量的计算资源
步骤四:训练一个SVM分类器(二分类)来判断这个候选框里物体的类别
- 每个类别对应一个SVM,判断是不是属于这个类别,是就是positive,反之nagative。
步骤五:使用回归器精细修正候选框位置:对于每一个类,训练一个线性回归模型去判定这个框是否框得完美。
细心的同学可能看出来了问题,R-CNN虽然不再像传统方法那样穷举,但R-CNN流程的第一步中对原始图片通过Selective Search提取的候选框region proposal多达2000个左右,而这2000个候选框每个框都需要进行CNN提特征+SVM分类,计算量很大,导致R-CNN检测速度很慢,一张图都需要47s。
2. Fast R-CNN
导言
有没有方法提速呢?答案是有的,这2000个 region proposal 不都是图像的一部分吗,那么我们完全可以对图像提一次卷积层特征,然后只需要将 region proposal 在原图的位置映射到卷积层特征图上,这样对于一张图像我们只需要提一次卷积层特征,然后将每个 region proposal 的卷积层特征输入到全连接层做后续操作。
但现在的问题是每个 region proposal 的尺度不一样,而全连接层输入必须是固定的长度,所以直接这样输入全连接层肯定是不行的。
1 解决重复计算的问题
Fast R-CNN由此应运而生。不过准确来说,他的灵感还是来源于SPP net: Spatial Pyramid Pooling(空间金字塔池化),其中引入了类ROI Pooling的机制来解决之前CNN输入图像大小必须固定的问题(由于有全连接层,所以卷积最后一层输出的参数数量必须固定,因而反推至输入img size也是固定的)简言之,CNN原本只能固定输入、固定输出,CNN加上SSP之后,便能任意输入、固定输出。神奇吧?
Fast R-CNN的 ROI pooling layer实际上是SPP-NET的一个精简版,SPP-NET对每个 proposal使用了不同大小的金字塔映射,而 ROI pooling layer只需要下采样到一个7x7的特征图(就一个尺度)。对于 VGG16网络 conv5_3有 512个特征图,这样所有 region proposal对应了一个 77512维度的特征向量作为全连接层的输入。
由此,Fast R-CNN可以解决一个关键的问题:重复计算。不需要每个region proposal都单独CNN跑一遍,可以整张图跑一下,一次性得到整张图的feature map,然后利用ROI Pooling来将各个region proposal在上面映射。这样可以大大提速。
2 网络的尾部进行修改(损失函数和边框回归)
R-CNN训练过程分为了三个阶段,而Fast R-CNN直接使用softmax替代SVM分类,同时利用多任务损失函数边框回归也加入到了网络中,这样整个的训练过程是端到端的(除去region proposal提取阶段)。
也就是说,之前R-CNN的处理流程是先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做box regression,而在Fast R-CNN中,作者巧妙的把box regression放进了神经网络内部,与region分类和并成为了一个multi-task模型,实际实验也证明,这两个任务能够共享卷积特征,并相互促进。
下面来看结构图
Fast R-CNN 结构图
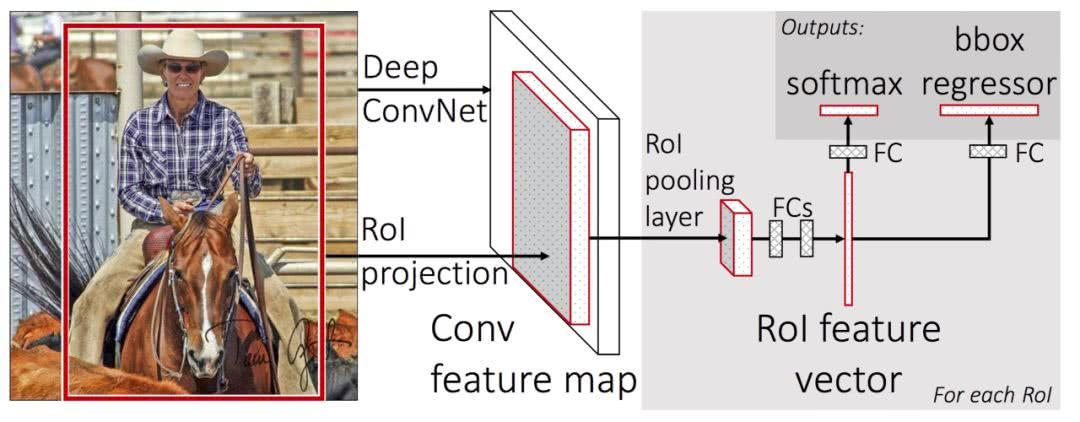
稍微总结一下
所以,Fast-RCNN很重要的一个贡献是成功的让人们看到了Region Proposal + CNN这一框架实时检测的希望,原来多类检测真的可以在保证准确率的同时提升处理速度,也为后来的Faster R-CNN做下了铺垫。
画一画重点:
R-CNN有一些相当大的缺点(把这些缺点都改掉了,就成了Fast R-CNN)。
大缺点:由于每一个候选框都要独自经过CNN,这使得花费的时间非常多。
解决:共享卷积层,现在不是每一个候选框都当做输入进入CNN了,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征
原来的方法:许多候选框(比如两千个)–>CNN–>得到每个候选框的特征–>分类+回归
现在的方法:一张完整图片–>CNN–>得到每张候选框的特征–>分类+回归
所以容易看见,Fast R-CNN相对于R-CNN的提速原因就在于:不过不像R-CNN把每个候选区域给深度网络提特征,而是整张图提一次特征,再把候选框映射到conv5上,而SPP只需要计算一次特征,剩下的只需要在conv5层上操作就可以了。同时,性能上也有很大的提升。
3. Faster R-CNN: end-to-end model
导言
Fast R-CNN存在的问题:存在瓶颈:选择性搜索,找出所有的候选框,这个也非常耗时。那我们能不能找出一个更加高效的方法来求出这些候选框呢?
解决:加入一个提取边缘的神经网络,也就说找到候选框的工作也交给神经网络来做了。
所以,rgbd 在 Fast R-CNN中引入 Region Proposal Network(RPN)替代 Selective Search,同时引入 anchor box应对目标形状的变化问题(anchor就是位置和大小固定的box,可以理解成事先设置好的固定大小的 proposal)
Faster R-CNN 结构说明
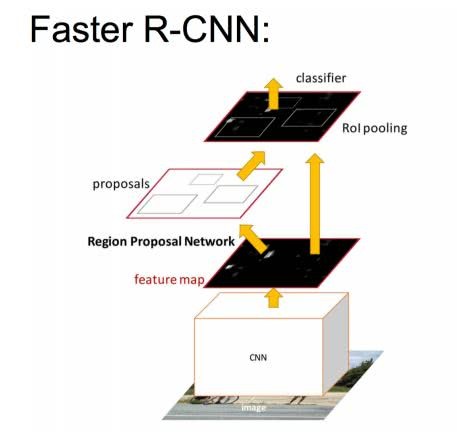
Faster R-CNN的网络有4部分组成:
- Conv Layers 一组基础的CNN层,由Conv + Relu + Pooling组成,用于提取输入图像的Feature Map。通常可以选择有5个卷积层的ZF网络或者有13个卷积层的VGG16。Conv Layers提取的Feature Map用于RNP网络生成候选区域以及用于分类和边框回归的全连接层。
- RPN,区域检测网络 输入的是前面卷积层提取的Feature Map,输出为一系列的候选区域RoI。
- RoI池化层 输入的是卷积层提取的Feature Map 和 RPN生成的候选区域RoI,其作用是将Feature Map 中每一个RoI对应的区域转为为固定大小的H×W的特征图,输入到后面的分类和边框回归的全连接层。
- 分类和边框回归修正 输入的是RoI池化后RoI的H×W的特征图,通过SoftMax判断每个RoI的类别,并对边框进行修正
步骤说明:
- 将样本图像整个输入到Conv Layers中,最后得到Feature Map。
- 将该Feature Map输入到RPN网络中,提取到一系列的候选区域
- 然后由RoI池化层提取每个候选区域的特征图
- 将候选区域的特征图输入到用于分类的Softmax层以及用于边框回归全连接层。
Faster R-CNN的4个组成部分,其中Conv Layers,RoI池化层以及分类和边框回归修正,和Fast R-CNN的区别不是很大,其重大改进就是使用RPN网络生成候选区域。
补充:
RPN简介
下面介绍点RPN的detail:
区域提议网络(RPN)以任意大小的图像作为输入,输出一组矩形的候选区域,并且给每个候选区域打上一个分数。如下图
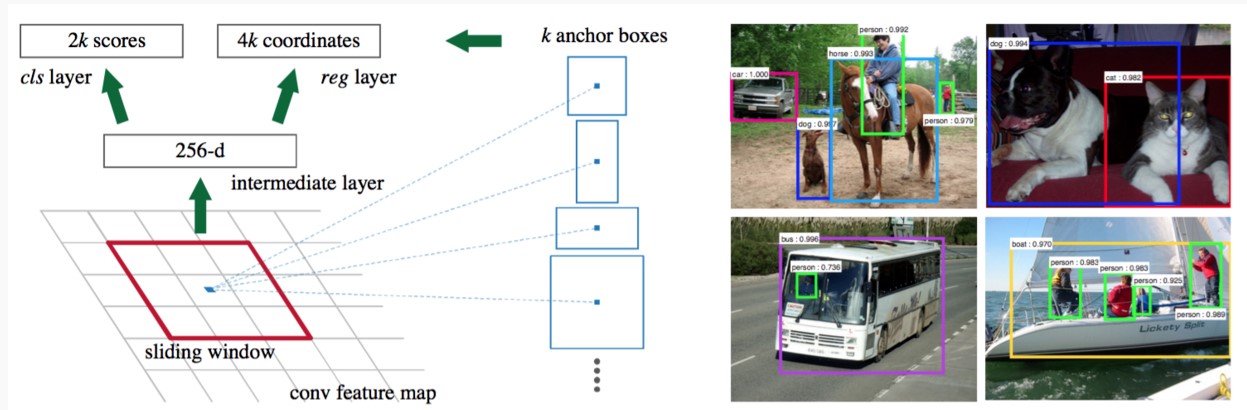
RPN输入的是前面Conv Layers提取图像的Feature Map,输出有两部分:
- 候选区域的位置信息(一个4维元组)
- 候选区域对应的类别(二分类,背景还是前景)。
为了得到上述的两种输出,要从输入的Feature Map上得到两种信息:
- 候选区域在原始输入图像的位置信息
- 每个候选区域对应的Feature Map,用于分类。
Anchor
前面提到由于池化层的降采样,Feature Map中的点映射回原图上,对应的不是某个像素点,而是矩形区域。考虑到候选区域可能有不同的大小,Faster R-CNN使用的是将每个Feature Map中的点映射到原图上,并以映射后的位置为中心,在原图取不同形状和不同面积的矩形区域,作为候选区域。 论文中提出了Anchor的概念来表示这种取候选区域的方法:一个Anchor就是Feature Map中的一个点,并有一个相关的尺度和纵横比。说白了,Anchor就是一个候选区域的参数化表示,有了中心点坐标,知道尺寸信息以及纵横比,很容易通过缩放比例在原图上找到对应的区域。
在论文中为每个Anchor设计了3种不同的尺度128×128,256×256,512×512,3种形状,也就是不同的长宽比W:H=1:1,1:2,2:1,这样Feature Map中的点就可以组合出来9个不同形状不同尺度的Anchor。下图展示的是这9个Anchor

设Feature Map的尺度为W×H,每个点上生成k个Anchor(k=9),则总共可以得到 $WHk$ 个Anchors。而每个Anchor即可能是前景也可能是背景,则需要Softmax层 cls=2k scores;并且每个anchor对应的候选区域相对于真实的边框有$(x,y,w,y)$4个偏移量,这就需要边框回归层4个偏移量,这就需要边框回归层 reg = 4k coordinates。
具体计算可以参考博客目标检测之R-CNN系列
训练
每个anchor即可能包含目标区域,也可能没有目标。 对于包含目标区域的anchor分为positive label,论文中规定,符合下面条件之一的即为positive样本:
- 与任意GT区域的IoU大于0.7
- 与GT(Groud Truth)区域的IoU最大的anchor(也许不到0.7)
和任意GT的区域的IoU都小于0.3的anchor设为negative样本,对于既不是正标签也不是负标签的anchor,以及跨越图像边界的anchor就直接舍弃掉。
由于一张图像能够得到WHkWHk个Anchors,显然不能将所有的anchor都用于训练。在训练的时候从一幅图像中随机的选择256个anchor用于训练,其中positive样本128个,negative样本128个。
4. Mask R-CNN
导言
神说要有光,然后就有了Kaiming He大神。哈哈开个玩笑。
Mask R-CNN其实采用并不复杂的方式对前辈进行 expand,完成 instance segmentation的任务
Mask R-CNN有如下特点:
简单直观:整个Mask R-CNN算法的思路很简单,就是在原始Faster-rcnn算法的基础上面增加了FCN来产生对应的MASK分支。即Faster-rcnn + FCN,更细致的是 RPN + ROIAlign + Fast-rcnn + FCN。
高速和高准确率:为了实现这个目的,作者选用了经典的目标检测算法Faster-rcnn和经典的语义分割算法FCN。Faster-rcnn可以既快又准的完成目标检测的功能;FCN可以精准的完成语义分割的功能,这两个算法都是对应领域中的经典之作。Mask R-CNN比Faster-rcnn复杂,但是最终仍然可以达到5fps的速度,这和原始的Faster-rcnn的速度相当。由于发现了ROI Pooling中所存在的像素偏差问题,提出了对应的ROIAlign策略,加上FCN精准的像素MASK,使得其可以获得高准确率。
易于使用:整个Mask R-CNN算法非常的灵活,可以用来完成多种任务,包括目标分类、目标检测、语义分割、实例分割、人体姿态识别等多个任务,这将其易于使用的特点展现的淋漓尽致。我很少见到有哪个算法有这么好的扩展性和易用性,值得我们学习和借鉴。除此之外,我们可以更换不同的backbone architecture和Head Architecture来获得不同性能的结果。
Mask R-CNN 结构图
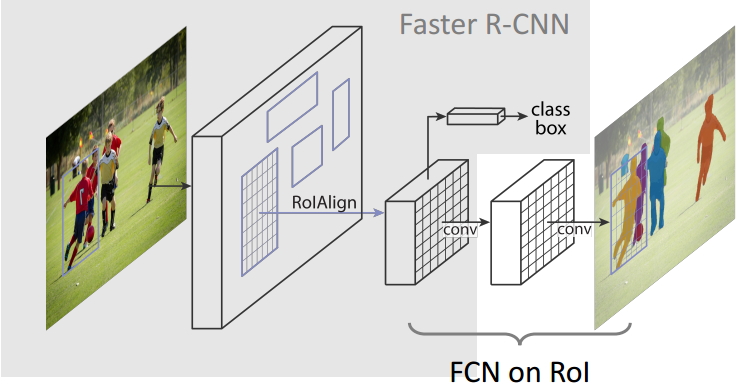
和Faster R-CNN的不同:
- 增加3rd分支 Mask branch:采用FCN
- 用ROIAlign替代ROI Pooling
- 最大的区别是:前者使用了两次量化操作,而后者并没有采用量化操作,使用了线性插值算法,这样分割会更加精确
- loss的计算
- $L = L_{cls}+ L_{box}+L_{mask}$,前两个一样,最后一个是新加的
- 其中$L_{mask}$仅仅定义在第K个mask上(假设该ROI是第K类object)
步骤说明
- 首先,输入一幅你想处理的图片,然后进行对应的预处理操作,或者预处理后的图片;
- 然后,将其输入到一个预训练好的神经网络中(ResNeXt等)获得对应的feature map;
- 接着,对这个feature map中的每一点设定预定个的候选区域ROI,从而获得多个ROI;
- 将这些候选的ROI送入RPN网络进行二值分类(前景或背景)和BB回归,过滤掉一部分候选的ROI;
- 对这些剩下的ROI进行ROIAlign操作(将原图对应ROI的区域映射到feature map上);
- 最后,对这些ROI进行分类(N类别分类)、BB回归和MASK生成(在每一个ROI里面进行FCN操作)。
5. 总结
表格来源于博客 Faster R-CNN论文笔记——FR,感觉总结得很棒

P.S.
本篇文档参考如下博客,特此鸣谢(ฅ´ω`ฅ)